PostgreSQL은 데이터를 어떻게 저장할까 — Cluster부터 Page까지
PostgreSQL의 내부 구조를 논리적 계층, 물리적 파일 레이아웃, Page 구조, 읽기/쓰기 동작까지 한 흐름으로 정리합니다.
주니어 개발자로 일하면서 데이터베이스의 중요성을 점점 더 느끼고 있다. 매일 SELECT, INSERT를 쓰지만, 그 쿼리가 실행될 때 PostgreSQL 안에서 무슨 일이 일어나는지는 제대로 모르고 있었다. 그래서 PostgreSQL이 데이터를 어떻게 저장하고 읽는지 가볍게 정리해보았다. 틀린 내용이 있을 수 있으니 양해 부탁드린다.
이 글에서는 가장 높은 수준의 논리적 구조부터 시작해서, 디스크의 물리적 레이아웃, 8KB Page의 내부, 그리고 실제 읽기/쓰기 동작까지 한 흐름으로 내려간다.
1. Database Cluster의 논리적 구조
PostgreSQL 서버 하나가 관리하는 데이터베이스 묶음을 Database Cluster라고 부른다. "클러스터"라는 이름 때문에 여러 서버가 모인 것처럼 보이지만, 실제로는 서버 1대 + 디스크 1곳이다.
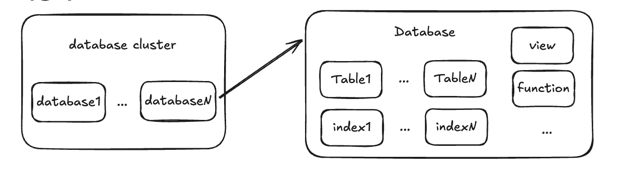
아파트 단지로 비유하면 이해가 쉽다.
| PostgreSQL 용어 | 비유 |
|---|---|
| Database Cluster | 하나의 아파트 단지 |
| Database | 단지 안의 각 동 (101동, 102동...) |
| Database Object (테이블 등) | 각 동 안의 세대 (101호, 201호...) |
Database끼리는 논리적으로 격리되어 있다. 101동에서 102동의 방을 직접 열 수 없듯이, DB A의 테이블을 DB B에서 직접 접근할 수 없다.
OID — 모든 객체의 주민번호
PostgreSQL은 내부적으로 모든 데이터베이스 객체를 OID(Object Identifier)라는 unsigned 4-byte 정수로 식별한다. 평소 개발할 때 직접 다룰 일은 거의 없지만, 시스템 카탈로그를 조회하거나 디버깅할 때 알아두면 유용하다.
-- 데이터베이스의 OID 확인
SELECT datname, oid FROM pg_database WHERE datname = 'sampledb';
-- 테이블의 OID 확인
SELECT relname, oid FROM pg_class WHERE relname = 'sampletbl';참고로 PostgreSQL의 전신인 POSTGRES는 모든 행(row)에도 OID를 자동 부여했다. 하지만 관계형 DB 원칙에 어긋나고, 32-bit 정수라 대량 데이터에서 고갈 위험이 있어서 v8.1에서 기본 비활성화, v12에서 완전히 제거됐다. 지금은 Primary Key를 쓰면 된다.
2. Database Cluster의 물리적 구조
논리적 구조를 봤으니, 이제 실제 디스크에 어떻게 저장되는지 보자.
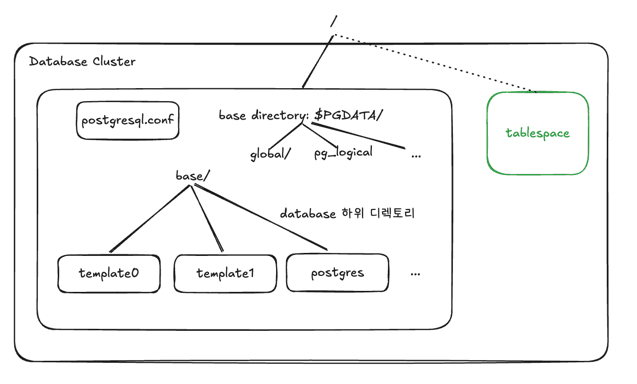
Database Cluster의 실체는 하나의 디렉토리(PGDATA)다. initdb 명령으로 생성되며, 이 안에 설정 파일, 데이터 파일, WAL 등 모든 것이 들어있다.
주요 설정 파일
| 파일 | 역할 |
|---|---|
postgresql.conf | 전체 설정 — 메모리, 커넥션 수, 로깅 등 |
pg_hba.conf | 클라이언트 인증 |
postgresql.auto.conf | ALTER SYSTEM으로 바꾼 설정 — postgresql.conf보다 우선 적용 |
주요 하위 디렉토리
| 디렉토리 | 역할 |
|---|---|
base/ | 데이터베이스별 데이터 파일 |
global/ | 클러스터 전체 공유 테이블 (pg_database 등) |
pg_wal/ | WAL (Write-Ahead Log) — 장애 복구의 기반 |
pg_xact/ | 트랜잭션 커밋 상태 — 절대 삭제 금지 |
pg_tblspc/ | Tablespace 심볼릭 링크 |
v10에서
pg_xlog→pg_wal,pg_clog→pg_xact로 이름이 바뀌었다. "log"라는 이름을 보고 삭제해도 된다고 오해하는 사용자가 많았기 때문이다.
데이터베이스 = 디렉토리, 테이블 = 파일
각 데이터베이스는 base/ 아래에 OID를 이름으로 한 디렉토리로 존재한다.
$ ls -ld base/16384
drwx------ 213 postgres postgres 7242 8 26 16:33 16384테이블과 인덱스는 그 안에 파일로 저장된다.
-- 테이블의 실제 파일 경로 확인
SELECT pg_relation_filepath('sampletbl');
-- 결과: base/16384/18740여기서 주의할 점이 있다. 테이블의 내부 식별자인 OID는 불변이지만, 실제 파일명인 relfilenode는 변할 수 있다.
SELECT relname, oid, relfilenode FROM pg_class WHERE relname = 'sampletbl';
-- relname | oid | relfilenode
-- ----------+-------+-------------
-- sampletbl | 18740 | 18740 ← 보통은 같지만...TRUNCATE, REINDEX, CLUSTER 같은 명령을 실행하면 relfilenode가 바뀐다. TRUNCATE가 DELETE FROM보다 빠른 이유 중 하나가 이것이다 — 행을 하나씩 지우는 게 아니라 파일 자체를 새로 만든다.
Fork — 테이블당 부속 파일
테이블 하나에는 데이터 파일 외에 2개의 부속 파일이 따라붙는다.
| Fork | 접미사 | 역할 |
|---|---|---|
| Fork 0 | (없음) | 실제 데이터 |
| Fork 1 | _fsm | Free Space Map — 각 Page의 빈 공간 추적 |
| Fork 2 | _vm | Visibility Map — Page 가시성 추적 (VACUUM 최적화) |
$ ls base/16384/18751*
base/16384/18751 # 데이터
base/16384/18751_fsm # 빈 공간 맵
base/16384/18751_vm # 가시성 맵_fsm과 _vm이 왜 필요한지는 이 글 뒤에서 다시 등장한다.
3. Page — 8KB 블록의 내부
테이블이 파일로 저장된다는 걸 알았다. 이제 그 파일 안쪽이 어떻게 생겼는지 보자.
PostgreSQL은 테이블 파일을 8KB 크기의 Page(Block)로 나눠서 관리한다. 각 Page 안에는 헤더, 포인터 배열, 실제 데이터인 Tuple이 정해진 구조로 들어있다.
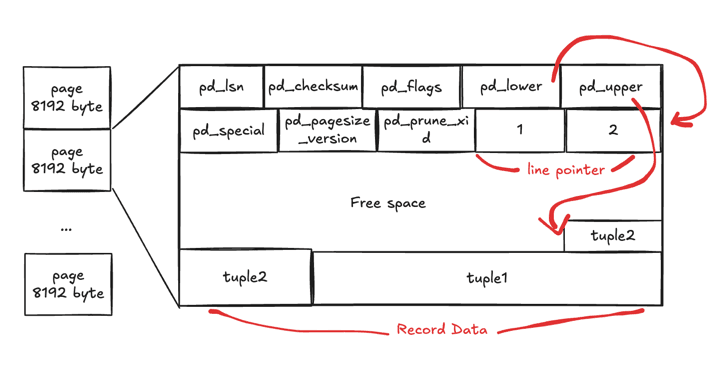
핵심은 방향이다. Line Pointer는 위에서 아래로 자라고, Heap Tuple은 아래에서 위로 쌓인다. 둘 사이의 빈 공간이 Free Space이며, pd_upper - pd_lower가 0에 가까워지면 Page가 꽉 찬 것이다.
Header Data — 24 bytes의 메타데이터
| 필드 | 역할 |
|---|---|
pd_lsn | 이 Page를 마지막으로 수정한 WAL 레코드의 위치 — 장애 복구 시 최신 여부 판단 |
pd_checksum | 데이터 손상 감지용 체크섬 |
pd_lower | Line Pointer 영역의 끝 (Free Space 시작점) |
pd_upper | 가장 최근 Tuple의 시작 (Free Space 끝점) |
pd_special | 특수 영역 시작 — 인덱스 Page에서 사용, 일반 테이블에서는 Page 끝과 동일 |
Line Pointer — 간접 참조의 힘
각 4 bytes짜리 포인터로, Tuple이 Page 안 어디에 있는지 가리킨다.
왜 직접 참조하지 않고 포인터를 거치냐? Slotted Page 구조의 핵심이다. Tuple의 물리적 위치가 바뀌어도 (예: VACUUM으로 재정리) 외부 참조(인덱스의 TID)를 수정할 필요가 없다. Line Pointer만 업데이트하면 된다.
TID — Tuple의 주소
PostgreSQL이 특정 행을 찾을 때 사용하는 주소 체계로, (Block Number, Offset Number) 쌍이다. Block Number는 몇 번째 Page인지, Offset Number는 Page 안에서 몇 번째 Line Pointer인지를 나타낸다.
SELECT ctid, * FROM sampletbl;
-- ctid | id | name
-- -------+----+------
-- (0,1) | 1 | Alice
-- (0,2) | 2 | Bob
-- (1,1) | 3 | Carol ← 두 번째 Page의 첫 번째 Tuple인덱스가 저장하는 것이 바로 이 TID다. 인덱스 → TID → Line Pointer → Tuple. 이 흐름을 이해하면 인덱스 스캔의 동작 원리가 보인다.
TOAST — 큰 데이터의 처리
하나의 Tuple이 약 2KB를 초과하면 Page에 직접 저장할 수 없다 (8KB Page에 여러 Tuple이 들어가야 하므로). 이때 PostgreSQL은 데이터를 압축하거나 별도의 TOAST 테이블에 분리 저장한다.
TEXT, JSONB, BYTEA 같은 대용량 컬럼이 있는 테이블에서 SELECT *가 느린 이유 중 하나다. 필요한 컬럼만 SELECT하는 습관이 중요하다.
4. 읽기와 쓰기 — 실제 동작
구조를 알았으니, 이제 데이터가 어떻게 쓰이고 읽히는지 보자.
Writing — INSERT가 Page를 바꾸는 과정
Tuple이 삽입되면 Page 내부에서 두 가지 변화가 동시에 일어난다. 새 Tuple은 Page 바닥의 Free Space에서 위로 쌓이고 pd_upper가 상승한다. 새 Line Pointer는 Header 아래에서 아래로 추가되며 pd_lower가 하강한다. Tuple이 추가될수록 양쪽에서 Free Space가 줄어드는 구조다. Free Space가 부족하면 FSM(_fsm 파일)이 빈 공간이 있는 다른 Page를 찾아준다.
Reading — Sequential Scan vs Index Scan
Sequential Scan
모든 Page의 모든 Tuple을 순서대로 읽는다. Page 0의 모든 Line Pointer를 순회하고, Page 1로 넘어가고, 끝까지 반복한다.
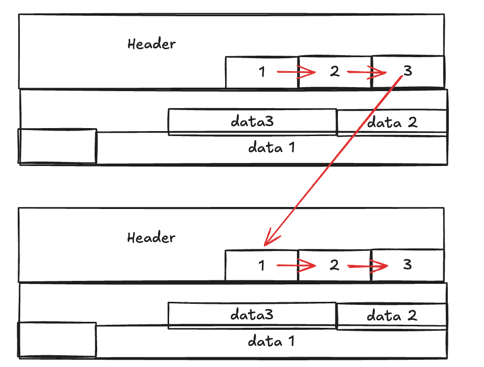
EXPLAIN SELECT * FROM users WHERE name = 'Alice';
-- Seq Scan on users (cost=0.00..25.88 rows=6 width=36)
-- Filter: (name = 'Alice')WHERE 조건이 있어도 적절한 인덱스가 없으면 Seq Scan이 발생한다. 하지만 테이블이 작으면 오히려 Index Scan보다 빠를 수 있다.
B-tree Index Scan
인덱스에서 TID를 찾고, 해당 Page의 Tuple로 직접 접근한다.
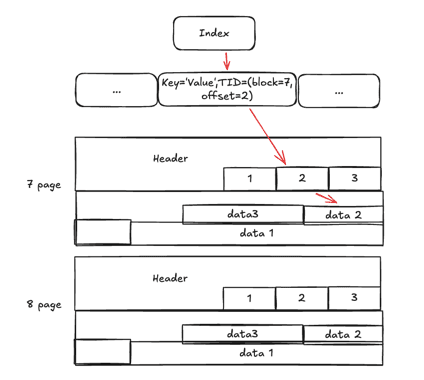
- B-tree 인덱스에서 조건에 맞는 index tuple 찾기
- index tuple에 저장된 TID 확인 (예:
block=7, offset=2) - 테이블 파일의 7번째 Page로 이동
- 2번째 Line Pointer가 가리키는 Heap Tuple 반환
EXPLAIN SELECT * FROM users WHERE id = 42;
-- Index Scan using users_pkey on users (cost=0.15..8.17 rows=1 width=36)
-- Index Cond: (id = 42)Seq Scan은 O(N), Index Scan은 O(log N). 데이터가 많을수록 인덱스의 가치가 커진다.
Bitmap Scan — 랜덤 I/O를 순차 I/O로
Index Scan의 문제는 랜덤 I/O가 많다는 것이다. 여기저기 Page를 뛰어다니면서 읽어야 한다.
Bitmap Scan은 이를 해결한다:
- 인덱스에서 조건에 맞는 TID를 전부 수집
- Block Number 기준으로 정렬
- Page 순서대로 순차적으로 읽기
랜덤 I/O를 순차 I/O로 변환해서 성능을 높인다. 중간 정도의 선택도(selectivity)를 가진 쿼리에서 주로 사용된다.
Index-Only Scan — 테이블을 아예 안 읽기
CREATE INDEX idx_users_name ON users(name);
-- 이 쿼리는 테이블 파일을 안 읽어도 된다
SELECT name FROM users WHERE name = 'Alice';
-- Index Only Scan using idx_users_name on users인덱스에 필요한 값이 이미 있으므로 테이블 파일(Heap)에 접근할 필요가 없다. 단, Visibility Map(_vm)을 확인해서 해당 Page의 모든 Tuple이 visible한지 검증해야 한다. 앞에서 본 _vm 파일이 여기서 쓰이는 것이다.
전체 흐름 정리
INSERT가 실행되면 FSM에서 빈 공간이 있는 Page를 찾고, Free Space에 Tuple을 쓰고, Line Pointer를 추가한 뒤, WAL에 변경을 기록한다.
SELECT가 실행되면 실행 계획을 수립한다. 인덱스가 없으면 Seq Scan으로 모든 Page를 순회하고, 인덱스가 있으면 B-tree에서 TID를 찾아 해당 Page/Tuple에 직접 접근한다.
이 글에서 다룬 흐름을 정리하면:
- 논리 구조: Database Cluster → Database → Table
- 물리 구조:
$PGDATA→base/OID→ relfilenode 파일 - Page 구조: 파일 → 8KB Page → Header + Line Pointer + Tuple
- I/O 동작: Page에 Tuple을 쓰고 읽는 방법
SQL 한 줄 뒤에서 이 모든 일이 일어나고 있다. 이 구조를 알면 VACUUM이 왜 필요한지, TRUNCATE가 왜 빠른지, 인덱스를 무작정 만들면 안 되는 이유가 자연스럽게 이해된다.